핵심정리 / Key Takeaways
- DeepSeek-V4-Pro는 Hugging Face와 ModelScope에 MIT 라이선스로 모델 가중치가 공개된 오픈소스 AI 모델입니다.
- 총 1.6조 개(1.6T) 파라미터, 토큰당 490억 개(49B) 활성화 파라미터를 사용하는 MoE 아키텍처를 적용했습니다.
- 1M 토큰 컨텍스트를 지원하며, 새로운 CSA + HCA 어텐션 아키텍처를 도입했습니다.
- 1M 토큰 시나리오에서 단일 토큰 추론 FLOPs는 이전 버전(V3.2)의 27% 수준으로 축소됐고, KV 캐시 사용량은 10% 수준으로 줄어 초장문 입력 메모리 사용량이 이전 대비 약 10배 감소했습니다.
- FP4 및 FP8 혼합 정밀도를 네이티브 지원하며, 추론 모드는 Non-think, Think High, Think Max의 3가지입니다.
- 벤치마크 기준으로 MMLU-Pro 등 코딩·수학 영역에서 OpenAI GPT-5.4와 동등한 수준, Claude Opus 4.5·4.6에 근접, Apex Shortlist 90.2%로 선두를 기록했습니다.
- 프로덕션 환경에서 FP8 기준 원활한 구동에는 H100 GPU 16장 이상이 필요합니다.
DeepSeek-V4-Pro는 최근 Hugging Face에 공개된 대형 오픈소스 AI 모델 가운데서도, 1M 토큰 컨텍스트, 대규모 MoE 아키텍처, 그리고 초장문 추론 효율성까지 함께 제시했다는 점에서 주목할 만합니다. 특히 이번 공개는 단순한 모델 릴리스가 아니라, AI 개발과 프로덕션 운영 관점에서 어떤 스펙과 자원 요구사항이 따라오는지를 함께 보여주는 사례에 가깝습니다.

DeepSeek-V4-Pro란 무엇인가: Hugging Face 공개와 오픈소스 AI의 의미

DeepSeek-V4-Pro의 저장소명은 deepseek-ai/DeepSeek-V4-Pro입니다. 모델 가중치는 Hugging Face와 ModelScope에 공개됐고, 라이선스는 MIT입니다. 즉, 이번 릴리스의 핵심은 단순 소개가 아니라 모델 가중치가 공개된 오픈소스 AI라는 점입니다.
이 공개 방식은 AI 개발 실무자에게 중요합니다. 모델 카드 수준의 설명이 아니라, 실제로 배포·검증·최적화 논의를 할 수 있는 출발점이 되기 때문입니다. 다만 이 글에서는 제공된 팩트 시트 범위 안에서만 기술적 핵심을 정리합니다.
DeepSeek-V4-Pro 핵심 스펙: 1.6T 파라미터, 49B 활성화, 1M 토큰 컨텍스트
| 항목 | 내용 |
|---|---|
| 모델명 | DeepSeek-V4-Pro |
| 저장소 | deepseek-ai/DeepSeek-V4-Pro |
| 공개 플랫폼 | Hugging Face, ModelScope |
| 라이선스 | MIT |
| 총 파라미터 | 1.6조 개 (1.6T Total Parameters) |
| 활성화 파라미터 | 490억 개 (49B Active Parameters per token) |
| 아키텍처 | MoE (Mixture of Experts) |
| 컨텍스트 윈도우 | 100만 토큰 (1M 토큰 컨텍스트) |
| 어텐션 구조 | CSA + HCA 하이브리드 어텐션 |
| 혼합 정밀도 | FP4, FP8 네이티브 지원 |
| 추론 모드 | Non-think / Think High / Think Max |
| 프로덕션 요구사항 | FP8 기준 H100 GPU 16장 이상 |
모델명
DeepSeek-V4-Pro
저장소
deepseek-ai/DeepSeek-V4-Pro
공개 플랫폼
Hugging Face, ModelScope
라이선스
MIT
총 파라미터
1.6조 개 (1.6T Total Parameters)
활성화 파라미터
490억 개 (49B Active Parameters per token)
아키텍처
MoE (Mixture of Experts)
컨텍스트 윈도우
100만 토큰 (1M 토큰 컨텍스트)
어텐션 구조
CSA + HCA 하이브리드 어텐션
혼합 정밀도
FP4, FP8 네이티브 지원
추론 모드
Non-think / Think High / Think Max
프로덕션 요구사항
FP8 기준 H100 GPU 16장 이상
숫자만 놓고 봐도 DeepSeek-V4-Pro는 전형적인 초대형 MoE 아키텍처 모델입니다. 총 파라미터는 1.6T지만, 실제 토큰당 활성화는 49B라는 점이 핵심입니다. 이 구조는 대규모 모델 크기와 토큰당 계산 효율을 함께 설명할 때 중요한 기준이 됩니다.
MoE 아키텍처와 1M 토큰 컨텍스트: DeepSeek-V4-Pro가 보여준 기술 포인트
MoE 아키텍처는 전체 파라미터를 항상 전부 활성화하는 방식이 아니라, 토큰 처리 시 일부 전문가를 선택적으로 활성화하는 구조입니다. 팩트 시트 기준으로 DeepSeek-V4-Pro는 총 1.6T 파라미터를 가지면서도 토큰당 49B 활성화 파라미터를 사용합니다.
여기에 더해 이 모델은 1M 토큰 컨텍스트를 지원합니다. 초장문 문맥을 처리할 수 있다는 점은 단순 마케팅 문구가 아니라, 아키텍처와 메모리 효율 설계가 함께 따라와야만 가능한 스펙입니다. 그래서 이번 릴리스에서 주목할 부분은 파라미터 규모 그 자체보다, 초장문 입력을 실제로 감당하기 위한 효율성 설계입니다.
CSA + HCA 어텐션 아키텍처
DeepSeek-V4-Pro는 새로운 하이브리드 CSA + HCA 어텐션 아키텍처를 도입했습니다. 제공된 기준 데이터에서 확인되는 사실은 두 가지입니다.
- 이 구조는 1M 토큰 시나리오에서 효율성 개선과 직접 연결됩니다.
- 이전 버전(V3.2)과 비교했을 때, 단일 토큰 추론 FLOPs와 KV 캐시 사용량이 모두 크게 줄었습니다.
초장문 추론 효율: FLOPs와 KV 캐시 절감

팩트 시트에 따르면 1M 토큰 컨텍스트 시나리오에서, DeepSeek-V4-Pro의 단일 토큰 추론 FLOPs는 이전 버전(V3.2)의 27% 수준으로 축소됐습니다. 이는 긴 문맥 입력에서 계산량을 억제하는 방향으로 설계가 진전됐다는 의미입니다.
메모리 측면에서도 변화가 명확합니다.
- KV 캐시 사용량은 이전 대비 10% 수준
- 초장문 입력 시 메모리 사용량은 이전 대비 약 10배 감소
즉, 1M 토큰 컨텍스트는 단지 최대 길이만 늘어난 것이 아니라, 그 길이를 다루는 데 필요한 연산과 메모리 비용을 함께 줄이려는 아키텍처 혁신과 묶여 있습니다. 이 점은 AI 개발과 시스템 설계 관점에서 매우 실무적인 변화입니다.
FP4·FP8 혼합 정밀도와 추론 모드: AI 개발 관점에서 봐야 할 운영 포인트
DeepSeek-V4-Pro는 FP4 및 FP8 혼합 정밀도를 네이티브 지원합니다. 이는 모델 효율성과 배치 전략을 논의할 때 중요한 요소입니다. 특히 하드웨어 자원과 처리량을 함께 고려해야 하는 AI 개발 환경에서는, 정밀도 지원 범위가 곧 운영 전략의 일부가 됩니다.
추론 모드는 다음 3가지로 제공됩니다.

- Non-think: 일상 작업과 빠른 응답
- Think High: 복잡한 문제 해결 및 계획
- Think Max: 최고 난이도 문제 해결
이 구성은 DeepSeek-V4-Pro가 단일 추론 스타일만 제공하는 모델이 아니라, 작업 난이도와 응답 성격에 따라 구분된 모드를 제공한다는 점을 보여줍니다. 다만 각 모드의 내부 구현 방식이나 추가 메커니즘은 제공된 데이터 범위 밖이므로, 여기서는 언급하지 않습니다.
벤치마크 성능: GPT-5.4, Claude Opus 4.5·4.6, Apex Shortlist 비교
팩트 시트에 포함된 벤치마크 요약은 DeepSeek-V4-Pro의 포지션을 비교적 명확하게 보여줍니다.
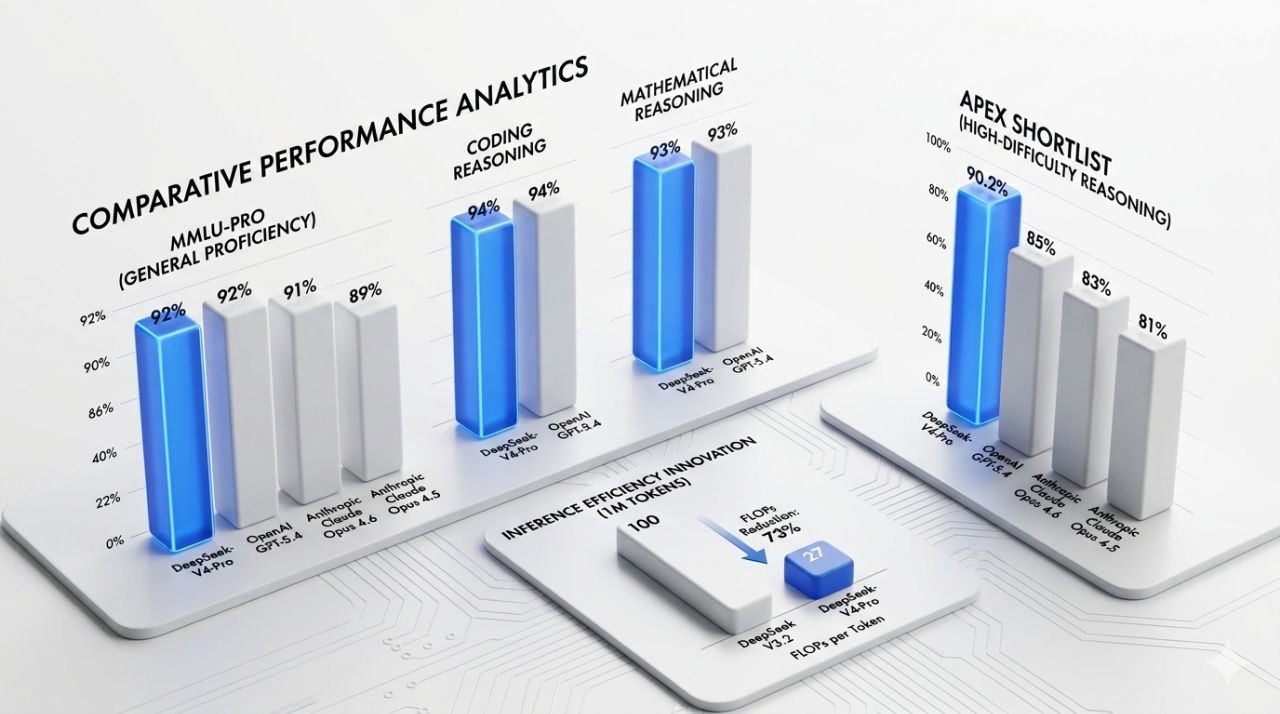
- MMLU-Pro 등 코딩 및 수학 벤치마크에서 OpenAI GPT-5.4와 동등한 수준(Matching)
- Anthropic Claude Opus 4.5 및 4.6에 근접한 성능
- 고난이도 추론 벤치마크 Apex Shortlist에서 90.2%로 선두
여기서 중요한 것은 과장된 해석이 아니라, 제공된 수치를 있는 그대로 읽는 것입니다. 즉, DeepSeek-V4-Pro는 공개된 팩트 기준으로 코딩·수학·고난도 추론 평가에서 강한 경쟁력을 보여줬습니다. 이 평가는 오픈소스 AI가 성능 측면에서도 상위권 상용 모델과 직접 비교되는 국면에 들어왔다는 점을 시사합니다.
하드웨어 요구사항: DeepSeek-V4-Pro를 프로덕션에서 돌리려면 무엇이 필요한가
하드웨어 요구사항은 매우 분명합니다. 팩트 시트 기준으로 DeepSeek-V4-Pro를 프로덕션 환경에서 FP8 기준 원활하게 구동하려면 H100 GPU 16장 이상이 필요합니다.

이 수치는 모델의 공개가 곧바로 누구나 가볍게 운영할 수 있음을 의미하지는 않는다는 점을 보여줍니다. 다시 말해, Hugging Face 공개와 오픈소스 AI라는 성격은 접근성을 높이지만, 실제 프로덕션 운영은 여전히 상당한 인프라 전제를 요구합니다.
같이 공개된 경량화 버전으로는 V4-Flash(284B)가 있으며, 기준 데이터에 따르면 이 버전은 더 적은 자원으로 구동 가능합니다. 다만 이 글의 중심은 DeepSeek-V4-Pro이므로, 상세 비교는 생략합니다.

DeepSeek-V4-Pro가 의미하는 것: Hugging Face, 오픈소스 AI, 그리고 AI 개발 실무
DeepSeek-V4-Pro를 정리하면 포인트는 명확합니다.
- Hugging Face와 ModelScope에 가중치가 공개된 오픈소스 AI 모델
- 1.6T / 49B 구조의 대규모 MoE 아키텍처
- 1M 토큰 컨텍스트 지원
- CSA + HCA 어텐션 기반 효율성 개선
- 초장문 추론에서 FLOPs 27%, KV 캐시 10%, 메모리 사용량 약 10배 감소
- FP4·FP8 혼합 정밀도와 3단계 추론 모드
- 벤치마크 기준 GPT-5.4 동급, Claude Opus 4.5·4.6 근접, Apex Shortlist 90.2%
- 프로덕션 운영에는 H100 16장 이상 필요
결국 이번 릴리스의 핵심은 단순히 “큰 모델이 또 나왔다”가 아닙니다. DeepSeek-V4-Pro는 Hugging Face에 공개된 오픈소스 AI 모델이면서, 1M 토큰 컨텍스트와 MoE 아키텍처, 그리고 초장문 효율성까지 함께 제시한 사례입니다. 따라서 이 모델은 AI 개발 관점에서 성능, 메모리, 추론 모드, 인프라 요구사항을 한 번에 검토해야 하는 대상이라고 보는 것이 가장 정확합니다.